2023年振り返り
2018年から振り返っているので、今年2023年も振り返っていきます。もう5年目らしい。
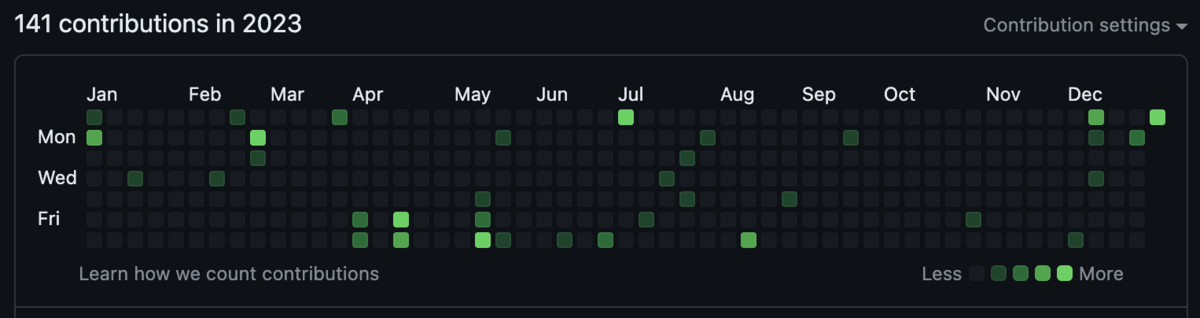
2023年の草は以上です。お疲れ様でした。
去年より減っていて何をしているのかというと、pushしていない雑多な開発をしたり3Dモデリングをしていて、残りは虚無です。
2023年の前半は東京に居なかったのだけど、色々が発生して東京に戻ってきました。この色々が原因であまり元気が無く、虚無に繋がっている気がするな...(とてもありがたいことに職は良い状態なのが救い...)
とりあえず振り返っていきます。
雑多な開発
冷静に考えるとChatGPTやCopilotが普通に生活に浸透してきたのも今年かもしれない。Copilotに関しては3月くらいから友達料を払って使っていて、主にデータ構造を詰め替えまくる部分やドキュメンテーションに関連する部分、定形パターンの実装でとても便利に使っている。逆にロジックを記述させてみると結構めちゃくちゃな結果になるので、このあたりの進化がとても楽しみ。早く人類を楽にしてくれ〜!
言語はC#、C++、Go、Pythonを趣味で多く使っていて、ついにRustとも和解できた。来年もやっていくぞ。
作ったものは、
- ブラウザでRTMPを受信するやつ
WebCodecsとgoのwasmを使って、ブラウザでwebsocket経由でRTMPを受信して再生できた (フレームレートがおかしいけれど)
— 𝕍𝕖𝕣𝕚𝕗𝕚𝕖𝕕 🧶 (@yutopp) 2023年7月22日
RTMPの送信も受信もgo-rtmpのみ https://t.co/7lnQAjJWDL pic.twitter.com/asvewI3LJi- 自作のgo-rtmpをwasm向けにビルドしてWebCodecsと組み合わせてブラウザ上でFLVを再生してみた。wasmはやはり面白い。自作ライブラリのメンテが滞っているのでモチベを上げて自分で使っていかなければ...
- オンラインコンパイラ(作りかけ)
- https://code.yutopp.net/ (ドメインも仮)
- すごい昔に鳥小屋というオンラインコンパイラを作っていたのだけれど、運用の知見がなさすぎてメンテが大変で継続できなかった。その反省を活かして今の知識ならどうするかなと作り直しているもの。多分まだ脆弱なのであまりめちゃくちゃなことはしないでくれよな!そのうちコードはpublicにする予定です。
あとは雑多なblenderとUnityのスクリプトとかだろうか。しっかりパッケージングする意識を持つようにしたい。
3Dモデリング


左が2022年までにできていたもの、右が2023年の最後まで作っていたもの。衣服はboothで購入したものを改変させてもらって重ねている。
3Dモデリングは、言語処理系やファイルフォーマットのライブラリを書いていて欠乏する栄養素を補うことができる。入力に対して決定的になるものを作る楽しさとは別に、見ていて楽しいので続けてしまう。
市販の衣服モデルを着せてみて思ったけれど、自分はこういったデザイン自体を考えることとテクスチャを描く工程に苦手意識がとてもあるので、来年はこれを克服していきたいなという気持ちがある。なにかおすすめの練習方法などがあったら教えてください。
その他
- LUUPに乗りまくっている
- 冷蔵庫にCHILL OUTしか入っていない
- 無限にホットケーキを焼いている
- Valheimのアップデートが楽しみ
まとめ
元気がないときにはしっかり休むのも大切だよな!という気持ちで過ごした1年だった。今年も色々な方にお世話になりました。ありがとうございました。
来年もあまり気負わずに楽しくものを作っていくぞ〜
2022年振り返り
2018年から振り返っているので、今年2022年も振り返っていきます。4年目か…

Q. これはなんですか?
A. 1年のpublicなGitHubの草です…
技術面でいうと、今年は全然publicな草を生やせていない…。かろうじて続けていたのは GitHub - yutopp/webgl-vgltf-sample: webgl example of VGltf(https://github.com/yutopp/VGltf) 周りな気がする。
UnityのWebGL向けビルドが結構面白くて、自作のglTFライブラリもスラスラ動いてしまった&ブラウザでインストールも特に必要なく動くというので、触っていきたい気持ちがある。IO周辺はTypeScriptで書いてしまって、Unityとブリッジすることでまあまあなものは作れそうな気がする。やっていきます。
それ以外でいうと、個人のラップトップ環境をM1 Macにしてしまったのも今年だ。慣れてしまえばバッテリー持ちが良い点とファンレスが快適だし、寝そべって雑に何かを書くような普段使いはこれでもう困らないかもしれないな〜という気持ちになっています。値上げの直前に運良く購入していたのでラッキーだった。
あとは引っ越しを2回と転職をしている。引っ越しも転職もしすぎだろ…。
そういえば昨日の最終出社ロボです(ありがとうございました…!) pic.twitter.com/u8vW4zeB8S
— ぶんちょう (@yutopp) 2022年11月3日
というわけでいまは東京にいません。いろいろバタバタしつつも、最終的にかなりやりたいことに近づいている気がする。頑張っていきたい。
それに伴って生活リズムがかなり真人間になってきたので、余裕が出てきたらまた草を茂らせていきたいですね。
技術に関係なさそうな部分は全く書いていないけれど、今年もいろいろな人にめちゃめちゃお世話になりました…。ありがとうございました。
来年もよろしくお願いします。
goを自分でビルドして標準ライブラリを改造してみる
gorountineのstackが再確保されたとき、stack上のポインタの値はどうなるのか - yutopp's blog で サラッと 動作が気になるので、runtime.stackDebugを4に書き換えた改造runtimeで再度出力を見てみる。 と書きました。
この記事は、自分でgoをビルドして標準ライブラリ(例としてruntime)を差し替える方法のメモです。
環境は以下
$ uname -v Darwin Kernel Version 22.1.0: Sun Oct 9 20:14:30 PDT 2022; root:xnu-8792.41.9~2/RELEASE_ARM64_T8103 $ go version go version go1.19.4 darwin/arm64
goのビルドをする
実際、Installing Go from source - The Go Programming Language に書いてあるとおりでgoのビルドが完了するのでやります。
ホストにgoがインストールされていれば、勝手にそれをbootstrapに使ってビルドをしてくれます。
# sourceを取ってくる $ wget https://go.dev/dl/go1.19.4.darwin-arm64.tar.gz # 解凍 $ tar -xf go1.19.4.darwin-arm64.tar.gz # ビルド $ cd go/src $ ./all.bash
これだけでテストが通るのを待てば完了。簡単すぎる...。
実際に使う場合は、ビルドした go ディレクトリ (多分これは自由に名前を変えて平気) の bin 以下のバイナリを呼びます。
$ go/bin/go version go version go1.19.4 darwin/arm64
runtimeの差し替え
さきほどのディレクトリの、src 以下に標準ライブラリ含めソースコードが配置されているので、これを変更してみます。
ここでは、例として runtime/stack.go を変更します。
# 雑にいじる場合はこんな感じで直に適当なエディタで開けばok (補完はこのままだと効かない)
$ code go/src/runtime/stack.go
試しにstackの初期化時に最悪なメッセージを表示するruntimeにしてみます。以下のように適当なprintを足してみましょう。
175: func stackinit() { 176: + println("進捗どうですか?") 177: if _StackCacheSize&_PageMask != 0 {
さて、この runtime をインストールしてみます。先程ビルドしたgo/bin/goを用いて、以下のコマンドを実行すれば良いようです [1]。
# -a は強制リビルド。-v はパッケージ名の表示 [2] $ go/bin/go install -a -v runtime
実行してみる
では適当なコードをビルドして実行結果を見てみましょう。以下を main.go という名前で保存します。
package main func main() { }
ビルド。
$ go/bin/go build main.go
実行してみます。
$ ./main 進捗どうですか?
最悪なgo runtimeの完成です。よかったですね。
[1] go - Golang Runtime recompile - Stack Overflow が参考になった。
goroutineのstackが再確保されたとき、stack上のポインタの値はどうなるのか
goroutineはstackful corountine[1]でありcontiguous stack[2]であるから、stackの延伸が必要なときは新たな別の領域のstackへのコピーが発生するはず。このとき、スタック上のポインタの値はどうなってしまうのだろう?という疑問を調べたメモです。
実験の環境は以下。
$ uname -v Darwin Kernel Version 22.1.0: Sun Oct 9 20:14:30 PDT 2022; root:xnu-8792.41.9~2/RELEASE_ARM64_T8103 $ go version go version go1.19.4 darwin/arm64
見てみる
Go: How Does the Goroutine Stack Size Evolve? | by Vincent Blanchon | A Journey With Go | Medium の記事を参考に、stackのポインタを保存してprintlnするコードを実行してみる。
(fmt.Printlnではなくprintlnを使っているのは、前者を用いるとxがescapeされるため。)
package main import ( "unsafe" ) func main() { var x [10]int p := &x[0] pp := unsafe.Pointer(&x[0]) up := uintptr(pp) var px [10]*int // ポインタの配列も px[5] = p println("=== origin") println(&x) // 同じ println(&x[0]) // 同じ println(p) // 同じ println(pp) // 同じ println(px[5]) // 同じ println(up) // 同じ a(x) // stackmoveを引き起こす println("=== after copy") println(&x[0]) // アドレスが変わる println(p) // 変わった値と同じ println(pp) // 変わった値と同じ println(px[5]) // 変わった値と同じ println(up) // *前の値のまま* println("=== write") println(x[0]) // 0 *(*int)(unsafe.Pointer(p)) = 10 println(x[0]) // 10 *(*int)(unsafe.Pointer(up)) = 20 // どこかに書き込んでしまってる println(x[0]) // 10 } //go:noinline func a(x [10]int) { var y [1000]int c(y) } //go:noinline func c(x [1000]int) { }
ビルドは以下のコマンドで行う。compile command - cmd/compile - Go Packages [3] の通り -m を指定して、エスケープされていないことを確認しておく(buildの出力が空であればok)。
$ go build -gcflags "-m" main.go && ./main
実行結果は以下。
=== origin 0x14000098ec0 0x14000098ec0 0x14000098ec0 0x14000098ec0 0x14000098ec0 1374390161088 === after copy 0x1400006fec0 0x1400006fec0 0x1400006fec0 0x1400006fec0 1374390161088 === write 0 10 10
最初に取得したアドレスは 0x14000098ec0。
after copy の後のアドレスは 0x1400006fec0 になっている。
つまり、スタックに書き込まれたポインタの値も変化しているのが分かる。一方で uintptr に変換した値 1374390161088 は変化がない。
というわけで、runtimeのstack.goを覗いてみると、 stack mapを取得してスタックフレームを書き換えていそうな一連の処理がある。
動作が気になるので、runtime.stackDebugを4に書き換えた改造runtimeで再度出力を見てみる。
const (
// stackDebug == 0: no logging
// == 1: logging of per-stack operations
// == 2: logging of per-frame operations
// == 3: logging of per-word updates
// == 4: logging of per-word reads
- stackDebug = 0
+ stackDebug = 4
stackFromSystem = 0 // allocate stacks from system memory instead of the heap
$ go/bin/go build main.go && ./main
stackalloc 32768
allocated 0x14000004000
stackalloc 2048
stackcacherefill order=0
allocated 0x14000046000
stackalloc 32768
allocated 0x1400004c000
stackalloc 2048
allocated 0x14000046800
stackalloc 32768
allocated 0x14000054000
runtime: newstack sp=0x14000046770 stack=[0x14000046000, 0x14000046800]
morebuf={pc:0x1044a22d4 sp:0x14000046770 lr:0x0}
sched={pc:0x104485684 sp:0x14000046770 lr:0x1044a22d4 ctxt:0x0}
stackalloc 32768
allocated 0x14000084000
stackalloc 32768
allocated 0x1400005c000
stackalloc 32768
allocated 0x14000104000
stackalloc 2048
stackcacherefill order=0
allocated 0x14000042000
stackalloc 2048
allocated 0x14000042800
runtime: newstack sp=0x14000046390 stack=[0x14000046000, 0x14000046800]
morebuf={pc:0x104482108 sp:0x14000046390 lr:0x0}
sched={pc:0x104481728 sp:0x14000046390 lr:0x104482108 ctxt:0x0}
stackalloc 4096
stackcacherefill order=1
allocated 0x14000118000
copystack gp=0x140000021a0 [0x14000046000 0x14000046390 0x14000046800] -> [0x14000118000 0x14000118b90 0x14000119000]/4096
0x140000021f0:0x0
0x14000002208:0x14000046388
adjust ptr 0x14000002208:0x14000046388 -> 0x14000118b88
0x140000021c8:0x0
0x140000021c0:0x0
adjusting runtime.heapBits.forwardOrBoundary frame=[0x14000118b90,0x14000118b90] pc=0x104481728 continpc=0x104481728
args
0x14000118b98:ptr:0x10b774900 # 0 5
0x14000118ba0:scalar:0x500000000000 # 0 5
0x14000118ba8:ptr:0x10b96bfff # 0 5
0x14000118bb0:scalar:0x400 # 0 5
0x14000118bb8:scalar:0x140000463d0 # 0 5
0x14000118bc0:scalar:0x0 # 0 5
0x14000118bc8:scalar:0x400 # 0 5
0x14000118bd0:scalar:0x1044941a0 # 0 5
adjusting runtime.heapBits.initSpan frame=[0x14000118b90,0x14000118c00] pc=0x104482108 continpc=0x104482108
locals 1/4 3 words 0x1044d003d
0x14000118be0:scalar:0x1 # 0 4
0x14000118be8:scalar:0x10 # 0 4
0x14000118bf0:ptr:0x10b774900 # 0 4
0x14000118bf8:scalar:0x14000046448 # 0 4
0x14000118c00:scalar:0x1044844bc # 0 4
0x14000118c08:scalar:0x10b774900 # 0 4
0x14000118c10:scalar:0x0 # 0 4
0x14000118c18:scalar:0x10b96bfff # 0 4
args
0x14000118c08:scalar:0x10b774900 # 0 0
0x14000118c10:scalar:0x0 # 0 0
0x14000118c18:scalar:0x10b96bfff # 0 0
0x14000118c20:scalar:0x104484214 # 0 0
0x14000118c28:scalar:0x14000046448 # 0 0
0x14000118c30:scalar:0x600001044841c8 # 0 0
0x14000118c38:scalar:0x10baa32a8 # 0 0
0x14000118c40:scalar:0x1 # 0 0
adjusting runtime.(*mcentral).grow frame=[0x14000118c00,0x14000118c50] pc=0x104484704 continpc=0x104484704
no locals to adjust
adjusting runtime.(*mcentral).cacheSpan frame=[0x14000118c50,0x14000118cc0] pc=0x1044844bc continpc=0x1044844bc
locals 0/3 2 words 0x1044cfae4
0x14000118ca8:scalar:0x10b96bfff # 0 0
0x14000118cb0:scalar:0x10455c348 # 0 0
0x14000118cb8:scalar:0x14000046508 # 0 0
0x14000118cc0:scalar:0x10447d804 # 0 0
0x14000118cc8:scalar:0x10455c340 # 0 0
0x14000118cd0:scalar:0x10447d7d0 # 0 0
0x14000118cd8:scalar:0x10b774700 # 0 0
0x14000118ce0:scalar:0x104494164 # 0 0
adjusting runtime.(*mcache).refill frame=[0x14000118cc0,0x14000118d10] pc=0x104483a88 continpc=0x104483a88
locals 1/2 1 words 0x1044cf845
0x14000118d00:ptr:0x1045bca90 # 0 1
0x14000118d08:scalar:0x14000046558 # 0 1
0x14000118d10:scalar:0x10447de08 # 0 1
0x14000118d18:scalar:0x1045bca68 # 0 1
0x14000118d20:scalar:0x10b96bfff # 0 1
0x14000118d28:scalar:0x10b774800 # 0 1
0x14000118d30:scalar:0x0 # 0 1
0x14000118d38:scalar:0x0 # 0 1
adjusting runtime.(*mcache).nextFree frame=[0x14000118d10,0x14000118d60] pc=0x10447d804 continpc=0x10447d804
locals 1/2 1 words 0x1044cf845
0x14000118d50:ptr:0x1045bca90 # 0 1
0x14000118d58:scalar:0x140000465c8 # 0 1
0x14000118d60:scalar:0x10447e39c # 0 1
0x14000118d68:scalar:0x1045bca68 # 0 1
0x14000118d70:scalar:0x10000104484110 # 0 1
0x14000118d78:scalar:0x10baa33c8 # 0 1
0x14000118d80:scalar:0x1 # 0 1
0x14000118d88:scalar:0x600100000065f8 # 0 1
adjusting runtime.mallocgc frame=[0x14000118d60,0x14000118dd0] pc=0x10447de08 continpc=0x10447de08
locals 3/8 4 words 0x1044d090f
0x14000118da8:ptr:0x1045339a0 # 0 5
0x14000118db0:scalar:0x0 # 0 5
0x14000118db8:ptr:0x0 # 0 5
0x14000118dc0:scalar:0x1044a28fc # 0 5
0x14000118dc8:scalar:0x140000465f8 # 0 5
0x14000118dd0:scalar:0x1044a2af8 # 0 5
0x14000118dd8:scalar:0x58 # 0 5
0x14000118de0:scalar:0x1044eec20 # 0 5
args
0x14000118dd8:scalar:0x58 # 0 2
0x14000118de0:ptr:0x1044eec20 # 0 2
0x14000118de8:scalar:0x14000046601 # 0 2
0x14000118df0:scalar:0x140000021a0 # 0 2
0x14000118df8:scalar:0x14000046678 # 0 2
0x14000118e00:scalar:0x10447816c # 0 2
0x14000118e08:scalar:0x14000046648 # 0 2
0x14000118e10:scalar:0x10447d818 # 0 2
adjusting runtime.newobject frame=[0x14000118dd0,0x14000118e00] pc=0x10447e39c continpc=0x10447e39c
no locals to adjust
args
0x14000118e08:scalar:0x14000046648 # 0 0
0x14000118e10:scalar:0x10447d818 # 0 0
0x14000118e18:scalar:0x10baa3458 # 0 0
0x14000118e20:scalar:0x49 # 0 0
0x14000118e28:scalar:0x10baa33c8 # 0 0
0x14000118e30:scalar:0x200 # 0 0
0x14000118e38:scalar:0x14000046678 # 0 0
0x14000118e40:scalar:0x104478000 # 0 0
adjusting runtime.acquireSudog frame=[0x14000118e00,0x14000118e80] pc=0x1044a2af8 continpc=0x1044a2af8
locals 3/4 4 words 0x1044cfddb
0x14000118e58:ptr:0x1045339a0 # 0 13
0x14000118e60:scalar:0x0 # 0 13
0x14000118e68:ptr:0x1400002b3b0 # 0 13
0x14000118e70:ptr:0x1400002aa00 # 0 13
0x14000118e78:scalar:0x14000046708 # 0 13
0x14000118e80:scalar:0x104477ed4 # 0 13
0x14000118e88:scalar:0x20 # 0 13
0x14000118e90:scalar:0x1045bca90 # 0 13
adjusting runtime.chanrecv frame=[0x14000118e80,0x14000118f10] pc=0x10447816c continpc=0x10447816c
locals 3/6 9 words 0x1044d137e
0x14000118ec0:scalar:0x0 # 0 12
0x14000118ec8:scalar:0x1000000000ca68 # 0 12
0x14000118ed0:ptr:0x1400010c058 # 0 12
0x14000118ed8:ptr:0x140000021a0 # 0 12
0x14000118ee0:scalar:0x10 # 0 12
0x14000118ee8:scalar:0x140000466f8 # 0 12
0x14000118ef0:scalar:0x1044aadb8 # 0 12
0x14000118ef8:scalar:0x14000046738 # 0 12
0x14000118f00:scalar:0x104485648 # 8 0
0x14000118f08:scalar:0x14000046738 # 8 0
0x14000118f10:scalar:0x104485654 # 8 0
0x14000118f18:scalar:0x1400010c000 # 8 0
0x14000118f20:scalar:0x0 # 8 0
0x14000118f28:scalar:0x14000002101 # 8 0
0x14000118f30:scalar:0x104485648 # 8 0
0x14000118f38:scalar:0x14000046768 # 8 0
args
0x14000118f18:ptr:0x1400010c000 # 0 3
0x14000118f20:ptr:0x0 # 0 3
0x14000118f28:scalar:0x14000002101 # 0 3
0x14000118f30:scalar:0x104485648 # 0 3
0x14000118f38:scalar:0x14000046768 # 0 3
0x14000118f40:scalar:0x1044a22d4 # 0 3
0x14000118f48:scalar:0x0 # 0 3
0x14000118f50:scalar:0x2 # 0 3
0x14000118f00:0x104485648
adjusting runtime.chanrecv1 frame=[0x14000118f10,0x14000118f40] pc=0x104477ed4 continpc=0x104477ed4
no locals to adjust
args
0x14000118f48:scalar:0x0 # 0 0
0x14000118f50:scalar:0x2 # 0 0
0x14000118f58:scalar:0x1045304e0 # 0 0
0x14000118f60:scalar:0x1400010c000 # 0 0
0x14000118f68:scalar:0x0 # 0 0
0x14000118f70:scalar:0x1044c7a24 # 0 0
0x14000118f78:scalar:0x1045304c0 # 0 0
0x14000118f80:scalar:0x0 # 0 0
adjusting runtime.gcenable frame=[0x14000118f40,0x14000118f70] pc=0x104485654 continpc=0x104485654
locals 1/2 1 words 0x1044cf845
0x14000118f60:ptr:0x1400010c000 # 0 1
0x14000118f68:scalar:0x0 # 0 1
0x14000118f70:scalar:0x1044c7a24 # 0 1
0x14000118f78:scalar:0x1045304c0 # 0 1
0x14000118f80:scalar:0x0 # 0 1
0x14000118f88:scalar:0x0 # 0 1
0x14000118f90:scalar:0x0 # 0 1
0x14000118f98:scalar:0x101000000000000 # 0 1
adjusting runtime.main frame=[0x14000118f70,0x14000118fd0] pc=0x1044a22d4 continpc=0x1044a22d4
locals 2/3 4 words 0x1044cfbb2
0x14000118fa8:scalar:0x140000021a0 # 0 8
0x14000118fb0:scalar:0x1044a2510 # 0 8
0x14000118fb8:scalar:0x1400004679e # 0 8
0x14000118fc0:ptr:0x140000467b0 # 0 8
0x14000118fc8:scalar:0x0 # 0 8
0x14000118fd0:scalar:0x0 # 0 8
0x14000118fd8:scalar:0x0 # 0 8
0x14000118fe0:scalar:0x0 # 0 8
adjust ptr 0x140000467b0 runtime.main
0x14000118fb8:0x1400004679e
adjust ptr 0x14000118fb8:0x1400004679e -> 0x14000118f9e
adjusting runtime.goexit frame=[0x14000118fd0,0x14000118fd0] pc=0x1044c7a24 continpc=0x1044c7a24
stackfree 0x14000046000 2048
stack grow done
=== origin
0x14000118ec0
0x14000118ec0
0x14000118ec0
0x14000118ec0
0x14000118ec0
1374390685376
runtime: newstack sp=0x14000118e50 stack=[0x14000118000, 0x14000119000]
morebuf={pc:0x1044c9b40 sp:0x14000118e50 lr:0x0}
sched={pc:0x1044c9ce8 sp:0x14000118e50 lr:0x1044c9b40 ctxt:0x0}
stackalloc 32768
allocated 0x14000090000
copystack gp=0x140000021a0 [0x14000118000 0x14000118e50 0x14000119000] -> [0x14000090000 0x14000097e50 0x14000098000]/32768
0x140000021f0:0x0
0x14000002208:0x14000118e48
adjust ptr 0x14000002208:0x14000118e48 -> 0x14000097e48
0x140000021c8:0x0
0x140000021c0:0x0
adjusting main.a frame=[0x14000097e50,0x14000097e50] pc=0x1044c9ce8 continpc=0x1044c9ce8
adjusting main.main frame=[0x14000097e50,0x14000097f70] pc=0x1044c9b40 continpc=0x1044c9b40
locals 1/4 11 words 0x1044d08ae
0x14000097f10:scalar:0x14000118ec0 # 0 254
0x14000097f18:ptr:0x0 # 0 254
0x14000097f20:ptr:0x0 # 0 254
0x14000097f28:ptr:0x0 # 0 254
0x14000097f30:ptr:0x0 # 0 254
0x14000097f38:ptr:0x0 # 0 254
0x14000097f40:ptr:0x14000118ec0 # 0 254
0x14000097f48:ptr:0x0 # 0 254
adjust ptr 0x14000118ec0 main.main
0x14000097f50:ptr:0x0 # 8 7
0x14000097f58:ptr:0x0 # 8 7
0x14000097f60:ptr:0x0 # 8 7
0x14000097f68:scalar:0x0 # 8 7
0x14000097f70:scalar:0x1044c7a24 # 8 7
0x14000097f78:scalar:0x1400008e000 # 8 7
0x14000097f80:scalar:0x0 # 8 7
0x14000097f88:scalar:0x0 # 8 7
adjusting runtime.main frame=[0x14000097f70,0x14000097fd0] pc=0x1044a23dc continpc=0x1044a23dc
locals 2/3 4 words 0x1044cfbb2
0x14000097fa8:scalar:0x140000021a0 # 0 8
0x14000097fb0:scalar:0x1044a2510 # 0 8
0x14000097fb8:scalar:0x14000118f9e # 0 8
0x14000097fc0:ptr:0x14000118fb0 # 0 8
0x14000097fc8:scalar:0x0 # 0 8
0x14000097fd0:scalar:0x0 # 0 8
0x14000097fd8:scalar:0x0 # 0 8
0x14000097fe0:scalar:0x0 # 0 8
adjust ptr 0x14000118fb0 runtime.main
0x14000097fb8:0x14000118f9e
adjust ptr 0x14000097fb8:0x14000118f9e -> 0x14000097f9e
adjusting runtime.goexit frame=[0x14000097fd0,0x14000097fd0] pc=0x1044c7a24 continpc=0x1044c7a24
stackfree 0x14000118000 4096
stack grow done
=== after copy
0x14000097ec0
0x14000097ec0
0x14000097ec0
0x14000097ec0
1374390685376
=== write
0
10
10
というわけで、goroutineに紐づくstackの全traceのframeのアドレスを書き換えていそうな雰囲気を感じられました。(雰囲気と言っているのは、そんなにしっかり挙動を追ったわけではないため...)
stackの値を書き換えるとしてもgoroutineの実行状態など気を使わないといけないでしょうし、それっぽいコード片があるのでもう少し詳しく追ってみたいですが、ひとまずstackの値は書き換わっていそうということが分かった。
結構実行時のコストにもなるのかなと思いましたが、そうでもないのかな〜。普通に使っていればエスケープされてheapに載っているケースのほうが多く、そこまで書き換えコストにならないとかなんでしょうか。
[1] 少なくともstackless corountineのような仕組みではないのでこう書いたけれど、語弊があるかもしれん。
[2] Changing segmented stacks to contiguous stacks で Contiguous stacks へのリンクが貼られている。
[3] 余談ですが、noescape directiveを使った高速化の攻めたライブラリがあって面白かった。 GitHub - lukechampine/noescape: Promise to the Go compiler that your Reads and Writes are well-behaved
2021年振り返り
2018年から振り返っているので、今年2021年も振り返っていきます。
生活
今年も昨年に引き続いて家にいる時間が長かったと思われる。現世は大変ですね…
おそらく今年最もヘビーに使っていたソフトウェアはDiscordで、これで好きなときに雑に話しながら作業やゲームなどをしていたため家にいても快適に過ごせた気がする。
開発
後述の労働の関係で、開発環境がWindows/Macメインになり、Linuxはほどほどに触るくらいになった。自分でも信じられんな…。なのでエディタもVSCodeとRiderをよく触る年でもあった。長年Emacsを使っていたので、魔改造キーバインドの依存症からの脱却にはたいへんつらい思いをしました。
言語は、趣味でも労働でもC#とGoをよく書いていたと思われる。途中でReScriptも触って快適さに感動していた。
自作言語
自作言語のランタイムをwasm対応したくらいしか進捗が無さそう。
基本コマンドは `rillc compile --target=wasm32-wasi hello_world.rill` だけでWASI用のwasm吐けるようになった… pic.twitter.com/kpRH6JwtJb
— ぶんちょう (@yutopp) 2021年1月12日
この辺りはcargoのtarget切り替えの仕組みを参考にして作った記憶がある。ツールチェインを各ターゲットに向けてまるごとビルドする構成と、コンパイラのパス探索を暗黙に行わないように作るのが王道なのかもしれんな、と雑に感じた思い出です。
これは小並感なのですが、GC無しかつゼロオーバーヘッドを目指した言語を趣味で作るの難しすぎない?というのがあって、雑に始めるとどう触っても実用できない状態が長く続いてしまう。先人の知恵は本当に偉大で、そこを車輪の再発明で再実装することが割と楽しいのだけど、これを実用できるまで作り切るのが大変すぎてどう時間を使おうかな~と悩んでいたら1年終わってしまった…。
自作ゲーム
昔あったgumonjiというゲームが忘れられなくて、最近Unityの知識もついてきたのでコツコツ作ろうとしている。
今日の進捗です pic.twitter.com/c1zjzkkxan
— ぶんちょう (@yutopp) 2021年11月7日
本当に見切り発車なので、このままだらだら開発を進めると自作言語と同じ轍を踏むことになるのが目に見えている…。
アバター動かしアプリ
普段使っているアバターを表示するアプリは自作なので、これも日々盆栽のようにだらだら開発し続けていた。
これの売りは、リアルとアニメ調の表情をいい感じに混ぜて表示できる点で、今は自分のアバターのデータのみ対応しているので好きに実装できている。
進捗ロボのfacial trackerみて pic.twitter.com/D0BQXx31z0
— ぶんちょう (@yutopp) 2021年8月29日
(笑顔のときの表情を素直に実装すると多分この動画のようにならないと思われる。)
仕組みとしてはARKitのblendshapeのパラメータをベースに、笑顔などのアニメ調の組み込みのblendshapeをmixして表示しているだけ。なので、PerfectSyncと巷で呼ばれるVRMモデルであれば汎用で対応して配布できるかもしれんなと思いつつ、これも面倒でなにもしていないまま1年が終わってしまった…。
他にはLeapMotion対応など細かい実験をしていた。
両手動いたからみて pic.twitter.com/HhVdj6eTjQ
— ぶんちょう (@yutopp) 2021年7月11日
ライブラリ
ordre
コードフォーマットに関する実装。paperを実装に落とし込む素振りでやった。
VGltf
今年もアクティブに開発できたので、これは引き続きやってきたい。
LT
遊び
ゲーム
雑に列挙すると、
- Valheim
- D4DJ
- Among Us
- 雀魂
- プリチャン
- プリマジ
- Minecraft
- ポナイト
- モンハン
- ICARUS
- NERTS! Online
- Noita
- JumpKing
あたりを触っていて、特にValheimはどっぷり遊んだと思われる。それでも180時間くらいだけれども…。
1人で遊べるゲームは無限に遊んでしまい時間が消滅するため、今年は意図してあまり触らないようにしていた。が、あまり進捗に変わりは無かったので来年は普通に遊ぶかもしれん(悲しC)
本
オワ…。壬生義士伝が面白かった(小並感)。
労働
4月に転をした。
転しました。よろしくお願いします!! pic.twitter.com/4bGyzSLI8j
— ぶんちょう (@yutopp) 2021年4月12日
いままでバックエンドをメインで色々してきたのですが、Unityメインで開発するようになりました。
実情として開発が高速でクライアントも基本毎週リリースし改善のサイクルを回しているすごい環境です。コードの品質と実装速度は両立するんだよなというのを地で行っており、やりがいがとてもあります。
年末に賞を頂いた。引き続きがんばりをやってきます。
🙏🙏🙏 pic.twitter.com/SzYPgRkOzs
— ぶんちょう (@yutopp) 2021年12月29日
エビフライ
落差がすごいんですが、今年始めて自炊で揚げ物をしました。油、こわすぎるだろ…。
命がけで揚げたエビフライみて pic.twitter.com/3fagwQZQ25
— ぶんちょう (@yutopp) 2021年9月11日
まとめ
3DモデリングやUnityは趣味で触れることが多かったが、労働でも触れられるようになり良い機会に恵まれた1年だったと思った。当然知らないことも多かったので、調べたり実験することに時間をたくさん使った。
来年は、すこし余裕をもって趣味の開発でスケジュールを切って進めるのをやってみたいとも思った。だらだら開発するのがめちゃめちゃ好きなのだけど、趣味でもしっかり完成を目指してもの作らんとな、という意識がかなり芽生えてきた…。やっていきます。
それでは、よいお年を…
AvatarMakerを支える技術 (cluster)
これは クラスター Advent Calendar 2021、8日目の記事です。
yutoppです。今はクラスターでソフトウェアエンジニアをしています。
さて、11/1にAvatarMakerという機能がリリースされました。めでたいですね。
今回は、このAvatarMakerの技術的な背景の一部分を紹介したいと思います。こんな感じで動いているんだな~と楽しんでいただけたら幸いです。
要件
基本的な部分に関しては以下のようになっています。
03の 顔の造形を変更できること は、プロシージャルに目のパーツや輪郭などが動くようになるわけでアバターの表現力が広がります。
一方で、メッシュのめり込みなど発生しやすくなりますし、デザイン・3Dモデル作成の量産・品質調整の難易度とのトレードオフになります。
04の 社内外のクリエイターがアバターのパーツをアップロードできること は、シンプルにやることが多くなります。
データの作成を開かれた技術・適切な権限で、セットアップの手順やトラブルシュートも社外の第三者が問題なく行える品質を見据えて設計・実装をする必要があります。
大変ですね。
設計


新たにglTFをやり取りするフローと、clusterからVRMをアップロードするフローを追加しています。
ユースケースとしては、
- クリエイターはDCCツールとUnityでアバターパーツを作り、glTFで出力
- AvatarMakerは、そのglTFを組み合わせてアバター全体を編集
- 編集が終わったらAvatarMakerがVRMとしてアバターを保存
- 以降、通常のアバターとして利用可能
を考えていて、clusterの既存のアバターのエコシステムと共存するようにしています。
実は、別にAvatarMakerはホームでなくても実行でき、VRMとして保存しなくてもアバターで動き回れる設計にしてあるので、そのうちワールドやイベントでリアルタイムに着替えながら遊べる未来もできたらいいですね。今後に期待…
実装
全体

AvatarMakerはライブラリとスタンドアロンの開発実験アプリとして独立して作りはじめ、その後clusterにライブラリとして組み込みました。
クリエイターがパーツをアップロードできるようにするためには、アップロード部分のコードを配布する必要がありますし、動作確認用のミニマルなソフトウェアも必要になることを見越してこうしています。
メリットとしては、最小限の依存関係でビルドが高速なので、開発イテレーションをたくさん回せる点。また、ライブラリとして設計することにより境界が明確になるため、アプリケーション本体への影響が読みやすい点などを感じています。
データ形式:glTF
独自形式にするとUGCとの親和性が微妙なので、今回はオープンなデータ形式であるglTF2.0を採用しました。

AvatarMakerのパーツは上記のようにhumanoidの状態でメッシュ分割されており、それぞれが独立したglTFのバイナリ形式で配布されます(clusterのVRMアバターと同じく難読化されます)。 それぞれに、”瞳のテクスチャはどれ” だとか ”肌のマテリアルはどうなっている” といった様々な情報を、glTFのextrasに詰めています。
VJson, VGltf
上記で書いたとおりglTFの拡張をかなり利用するつもりだったので、丁度いい実装はないかなということで自作のライブラリをプロダクトに導入しました。glTFのimport/exportと、VRMのexportに利用しています。
この点は技術選定で弊社TechLeadにも相談したのですが、自作ライブラリの導入にGoサインが出るのはなかなか狂気で良いなと密かに思いました。
forkせずに公開されている実装をそのまま使っています。glTFの拡張をヘビーに使っていますが、ライブラリのコードベースには一切手を加えずに対応できているので便利だと思います。
サーバーサイド合成 vs クライアントサイド合成
有料のパーツなどが発生した場合にサーバーサイドでパーツを合成したほうが堅牢だという話がありましたが、今回はクライアントサイドで合成しています。
既存VRMアバターと同様の難読化形式で配信する前提を置けば、Unity側で合成したほうがリアルタイムに着替えられますし、パーツごとに細かくデータをロードできてさわり心地も良いと思われます。デバッグもしやすいですしね。
パーツ合成、切り替えで毎回やるか・export時に一度か
AvatarMakerのパーツは切り替えるたびにhumanoidのskeletonを差し替えて1つのAvatarに合成しています。
最初は複数のパーツごとにhumanoidを重ねて描画していました。これは、skeletonの付け替えコストが重たいと想像していたためです。
しかし、skeletonの付け替えを試したところ全くコストにならず、フレーム落ちにも気づかない程度だったので、今はhumanoidのボーン構造をマージしたものに付け替えて単一のhumanoidを作るようになっています。
テクスチャ合成・カラーバリエーション
AvatarMakerは、瞳・ハイライト・眉毛・まつ毛・アイラインなどなど(他にもたくさんあります)、1つのパーツにテクスチャがもりもりに入っています。

これらの複数のテクスチャを重ねて描画し・色味の変換も行うシェーダを今回実装しています。シェーダで描画しているのでリアルタイムに合成を行っても高速で感動しました。
最初はイケイケのCustomRenderTextureを用いて実装していたのですが、モバイルで真っ黒になるなど破滅したので、古典的な1x1のmeshをorthographicに描画するシェーダに途中で書き換えています。悲しいですが枯れた技術は今も最高ということです。
マテリアル問題
clusterのカスタムアバター制限に収まるようにテクスチャとマテリアルを設計しています。AvatarMaker専用の特製アバターアップロードAPIなどはなく、平等に同じAPI経由で作っています。
マテリアルの質感が同じ部分は、上記のシェーダでテクスチャを1枚に重ねてマテリアルを1つにまとめるなど工夫しています。アバター上限解放が先にリリースされていて欲しかったですね(乞うご期待…)
メモリ枯渇問題
開発中は最高のテクスチャをそのままに2kでデータを配布していましたが、案の定 iOSデバイス がメモリ枯渇でクラッシュするようになりました(それはそう)。
なので、すべて1kテクスチャに変換し合成時に1テクスチャのみ2kにupconvertするようにしています。なんと、2kのテクスチャを1kにするとメモリ使用量が4分の1になります(それはそう)。
いまよく考えるとupconvertもしなくても良い気がしてきたので、今後軽量化する可能性があります。
clusterでVRMアバターにした状態で使う場合は、サーバーで軽量化されて配信されているのでそこまで負荷にはなっていないはずです。
IL2CPP対応
想像の5億倍 IL2CPPで問題が発生しました。やはり自作ライブラリを動かすときはIL2CPPが鬼門になると学びましたね…。
一部ですがどのような罠にハマったかを紹介します(Unityは2019.4.22fです)。
- checkedの範囲が変わる
- Type/TypeInfoのGetCustomAttributesで返ってくるインスタンスがキャッシュされていそう (実装依存っぽいですが…)
- code strippingによって静かに実行時エラーが発生
最後の方は (Windows, Mac, iOS, Android, Linux) x IL2CPPビルドで動作確認するような用心深さになりました。
さいごに
いかがでしたか?
開発以外にもたくさんの人々の力によってリリースされたAvatarMakerの技術的裏側の紹介でした。今後も開発を続けていくので、よろしくお願いいたします。
クラスター広告
クラスターは本物の3DCGクリエイターを募集しています。
謝辞
【Jump King】最難関超鬼畜ゲーをクリアします!!!ぺこ!【ホロライブ/兎田ぺこら】 - YouTube
開発初期にこの配信を見て精神を保っていました。感謝します。
2020年振り返り
2018年から振り返っているので、今年2020年も振り返っていきます。
今年は虚無の年でした…。
開発
Go、HCL、Rust、Elm、OCaml、C#、HLSL、TypeScript あたりを書いていたように思います。特段あたらしい言語に手を出した感じしないですね。
基本的に、CI/CDの仕組みを楽にしたり、ビルドやテスト時間の短縮、複数人での設計や品質まわりのバランスを無限に考えていた気がします。これどうする…?
あとは今まで適当に書いていた部分の調べ直しをしたり、GCPで消耗なくサービスのデプロイができないかの試行錯誤や雑スクリプトを書きなぐったり、ちょいちょいOSSにPRを出したりでしょうか…。形にしたい。
趣味で作ったリポジトリ
toy-runner
RustのFutureのexecutorの本当コアな部分を、Fahrenheit | Futures-rs を参考に書いていました。
Wakerあたりの気持ちが分かった気になっていましたが、今読むと疑問点がいくつかありますね… (スケジューラあたり)。
こういうものを書いたらすぐに記事にしよう!
yterm
Rustでgtkを用いてターミナルエミュレータを自作しようと思い立って途中まで書いたものです。UIスレッドとロジックのスレッドが分離しています。IMも使えます。
純粋にテキストエディタのレンダリング部分をどう書くのか調べようと思いたち、その前にCUIのテキストエディタをレンダリングできるターミナルエミュレータを作ればいいのでは?!と道を逸れていきました。常用くらいまで作りたいですが、いつになるか。
同人誌
今年も同人誌として合同誌を2冊出しました。
進捗大陸07の自分の担当では、自作言語の改造ログを書きました。型クラスの実装がかなり大変でした…。
進捗大陸08では今までとは毛色を変えて、UnityURP でトゥーンシェーダを書く解説を書きました。自分でシェーダを書く際に調べて気になったところにはすべて解説を差し込んだので、役に立ってほしい!
全員分面白い記事が集まっているので、よろしければ手にとっていただけると嬉しいです(宣伝)。
モデリング
頭も動くようにしたら良すぎて笑ってしまう pic.twitter.com/9erHKk6Orl
— ぶんちょう (@yutopp) July 25, 2020
去年まで作っていた3Dモデルに更に手を加えて、iOSのARKitのデータを使ってリアルタイムに現実と同期して表情を動かせるようにしていました。
blenderのfacial rigももっと改良したり、モーションデータも取得して動かすようにしたい…!
労
今年は転をしていない。来年は…
まとめ
今年は本当に進捗が少ない年でした。まずいです。
主な原因は謎の疲れにより色々とダラダラ後回しにしたことだと思っています。謎の疲れは、おそらく環境の変化だったり、労だったり、タスクが頭の中で散らばって気疲れなどがありそうでした。
とりあえず反省を活かして、
- タスクをGitHubのprojectで細かくメモする self · GitHub
- WriteCodeEveryDayを毎日時間をとってDiscordでやる
をして、来年は毎日コツコツやっていく年を目指していきをしていきます。
それではよいお年を…